|
I am a research scientist at Stability.ai, working on text-to-image and text-to-video models. Before that I was PhD studet at Institute for Technical Informatics, TU Graz and Complexity Science Hub, Vienna. I try to understand how/why deep learning works. I am a proud member of Stable Diffusion 3 . Email / Google Scholar / Twitter / Github / Book Office Hour |

|
|
|
|
I'm interested in deep learning, optimization/generalization and sparsity. Much of my research is about understaning deep learning phenomena. |
-1.png)
|
Rahim Entezari*, Mitchell Wortsman, Olga Saukh Hanie Sedghi, Ludwig Schmidt, arXiv Despite the success of transfer learning paradigm for various downstream tasks, still a question remains: what data and method should be used for pre-training? We study the effect of the pretraining data distribution on transfer learning in the context of image classification, investigating to what extent the choice of pre-training datasets impacts the downstream task performance. |
|
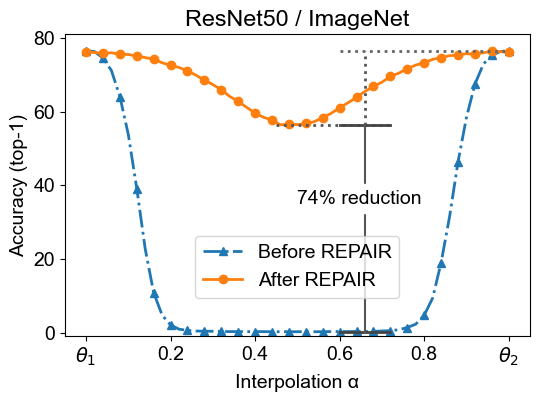
Keller Jordan*, Hanie Sedghi, Olga Saukh, Rahim Entezari, Behnam Neyshabur Accpeted at ICLR, 2023 arXiv In this paper we look into the conjecture of Entezari et al. (2021) which states that if the permutation invariance of neural networks is taken into account, then there is likely no loss barrier to the linear interpolation between SGD solutions. First, we observe that neuron alignment methods alone are insufficient to establish low-barrier linear connectivity between SGD solutions due to a phenomenon we call variance collapse: interpolated deep networks suffer a collapse in the variance of their activations, causing poor performance. Next, we propose REPAIR (REnormalizing Permuted Activations for Interpolation Repair) which mitigates variance collapse by rescaling the preactivations of such interpolated networks. |
|
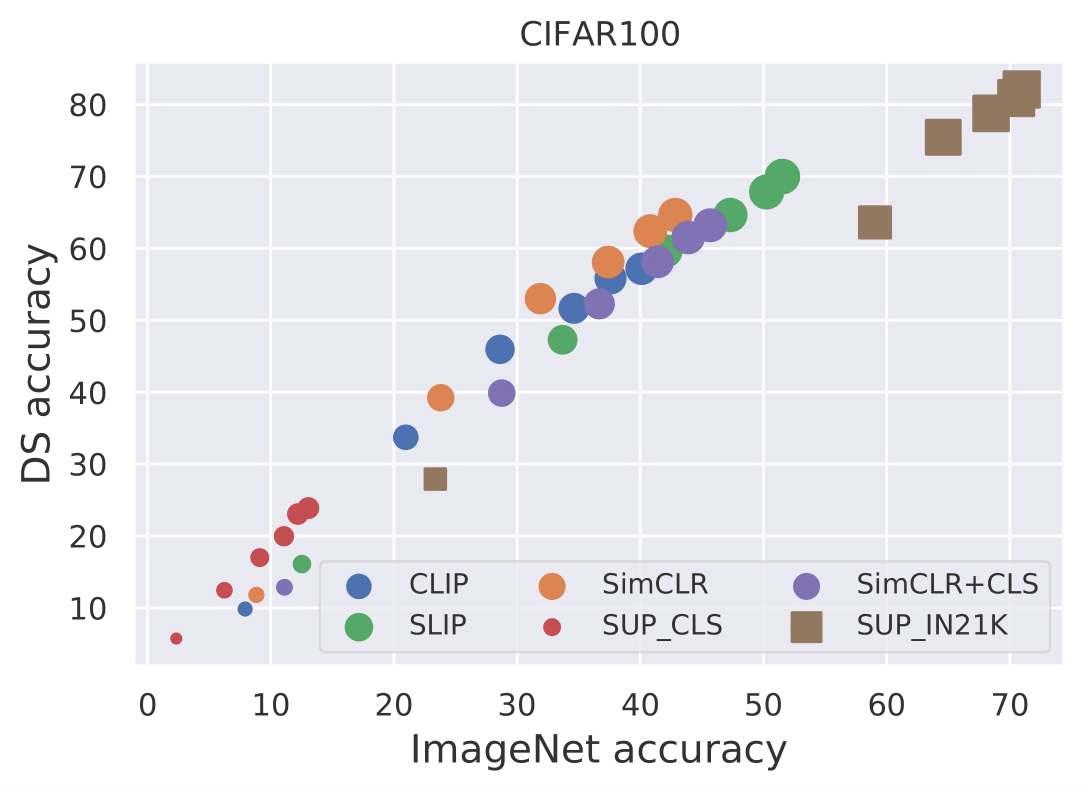
M. Moein Shariatnia*, Rahim Entezari*, Mitchell Wortsman*, Olga Saukh Ludwig Schmidt, ICML Pre-training: Perspectives, Pitfalls, and Paths Forward, 2022 Paper There are two prevailing methods for pre-training on large datasets to learn transferable representations: 1) supervised pre-training on large but weakly-labeled datasets; 2) contrastive training on image only and on image-text pairs. While supervised pre-training learns good representations that can be transferred to a wide range of tasks, contrastively trained models such as CLIP have demonstrated unprecedented zero-shot transfer. In this work we compare the transferability of the two aforementioned methods to multiple downstream tasks. |
|
Francesco Corti*, Rahim Entezari*, Sara Hooker, Davide Bacciu, Olga Saukh ICML Hardware Aware Efficient Training workshop, 2022 arXiv We study the impact of different pruning techniques on the representation learned by deep neural networks trained with contrastive loss functions. Our work finds that at high sparsity levels, contrastive learning results in a higher number of misclassified examples relative to models trained with traditional cross-entropy loss. |
|
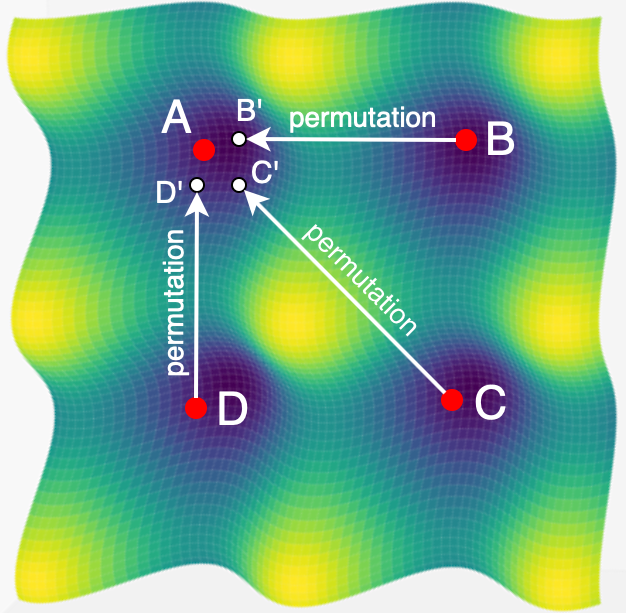
Rahim Entezari, Hanie Sedghi, Olga Saukh, Behnam Neyshabur Accpeted at ICLR, 2022 Twitter / arXiv We conjecture that if the permutation invariance of neural networks is taken into account, SGD solutions will likely have no barrier in the linear interpolation between them. |
|
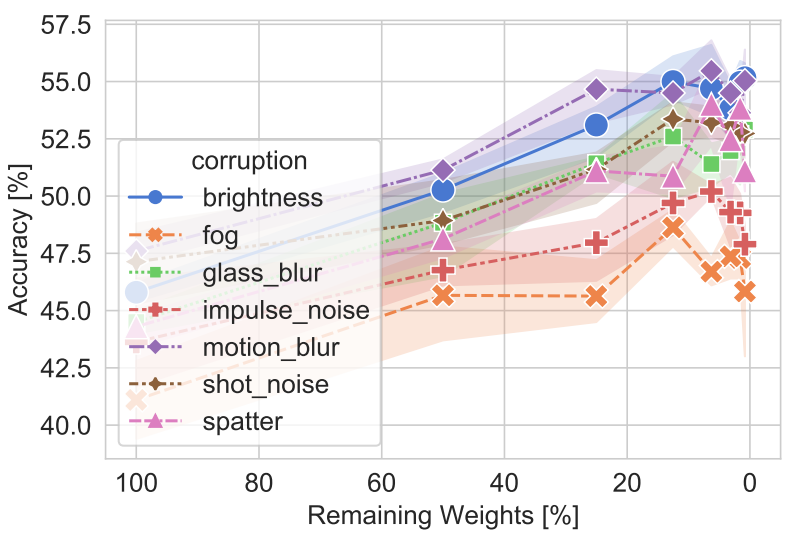
Lukas Timple*, Rahim Entezari*, Hanie Sedghi, Behnam Neyshabur, Olga Saukh ICML Overparameterization workshop, 2021 Paper We show that, up to a certain sparsity achieved by increasing network width and depth while keeping the network capacity fixed, sparsified networks consistently match and often outperform their initially dense versions. |
|
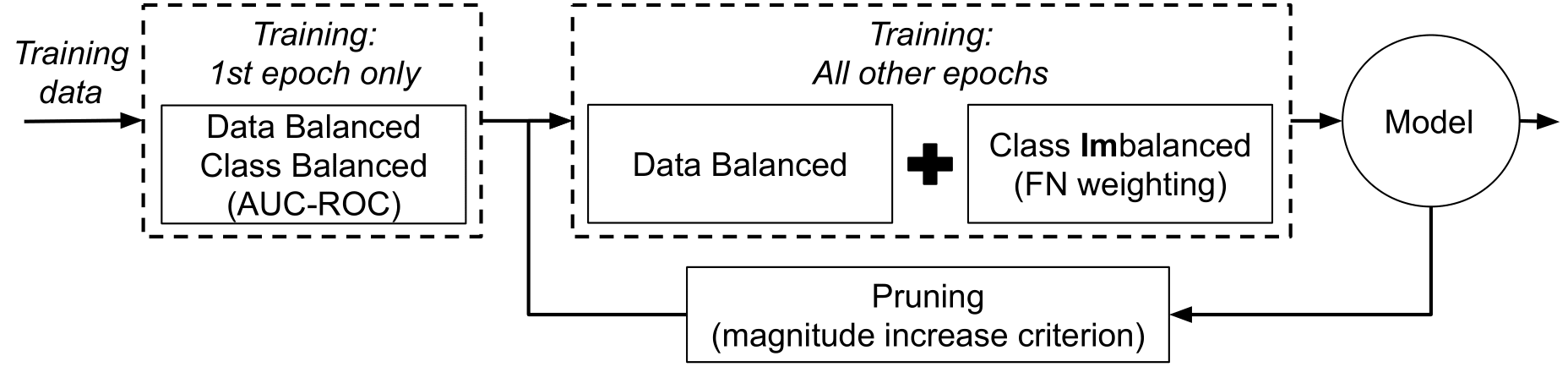
Rahim Entezari, Olga Saukh IEEE Second Workshop on Machine Learning on Edge in Sensor Systems (SenSys-ML), 2020 arXiv we propose an iterative deep model compression technique, which keeps the number of false negatives of the compressed model close to the one of the original model at the price of increasing the number of false positives if necessary. |
|
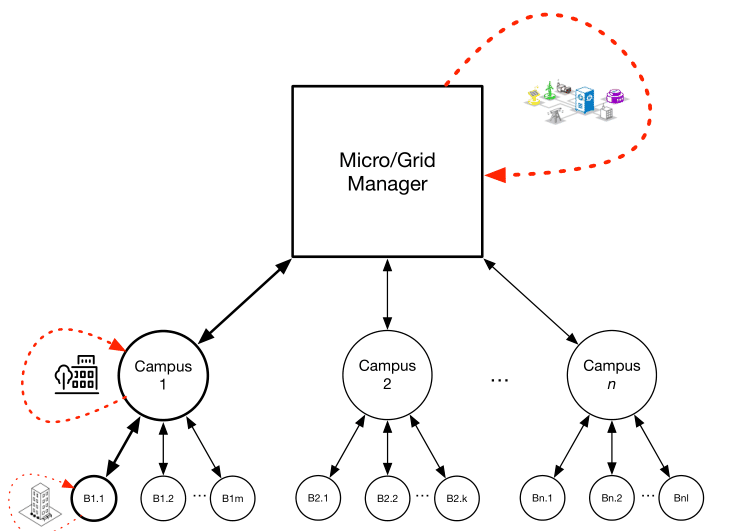
Grigore Stamatescu, Rahim Entezari, Kay Roemer, Olga Saukh IEEE 25th International Conference on Parallel and Distributed Systems (ICPADS), 2019 Paper we present a hierarchical energy system architecture with embedded control for network control in microgrids. |
|
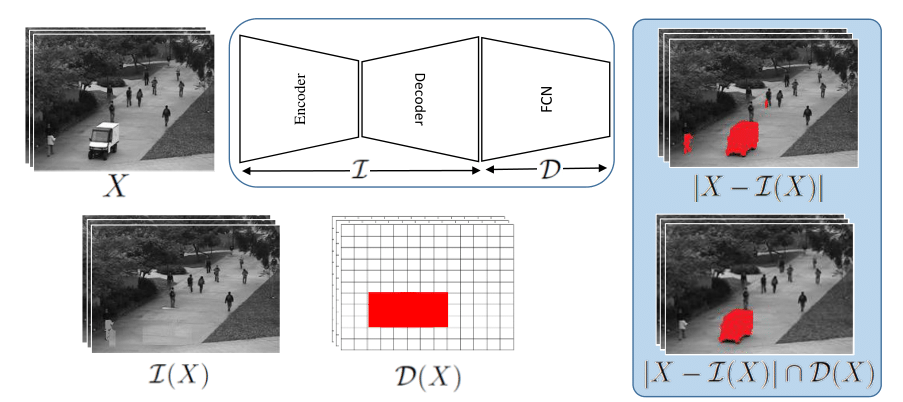
Mohammad Sabokrou, Masoud Pourreza, Mohsen Fayyaz, Rahim Entezari, Mahmood Fathy, Juergen Gall, Ehsan Adeli Asian Conference on Computer Vision (ACCV), 2018 arXiv We propose an end-to-end deep network for detection and fine localization of irregularities in videos (and images). |
|
|